
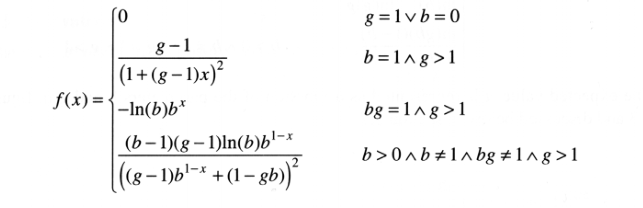
PDF of the MBBEFD distribution
The MBBEFD Distribution
After two years, the MBBEFDLite package for R is finally mature! As a brand-new actuary, in my first job, I had the privilege of working with Dr. Stefan Bernegger at Swiss Reinsurance. Albeit I did not have much to do with him—I was a one-exam, no experience new actuary and he was a PhD. in nuclear physics and already a world-reknown actuary—Dr. Bernegger treated me as the scholar and gentleman he is and made time to explain what we were doing and why. One of his best known contributions to actuarial science is his introduction in 1997 of the Maxwell-Boltzmann Bose-Einstein Fermi-Dirac family of curves to (re)insurance exposure rating. The curves, thankfully known by their acronym MBBEFD, are smooth two-parameter curves that range from 0 to 1, or no-loss to complete loss in insurance terms.
MBBEFDLite Package
Over the course of my career I have had many opportunities to use these curves when exposure rating accounts or building stochastic models. While I have implemented this in Excel, painfully, I tend to do so in R, which is much more apropos for statistical work. A number of years ago, I looked through CRAN and saw the excellent mbbefd package, written by three actuaries/statisticians who are well-known in the reinsurance world: Drs. Christophe Dutang, Giorgio Spedicato, and Markus Gesmann. The package is a tour-de-force and does significantly more than implement the simple (limited) MBBEFD commonly used in reinsurance. Also, or because of this, it has a number of dependencies, which means installing other packages. My philosophy is to do my best to reduce dependency hell. Therefore, I wrote my own, simple, package called MBBEFDLite.
The nascent MBBEFDLite package worked well enough for my purposes, followed CRAN styles, and was reasonably fast given that the heavy-lifting was done in C. One of the functions of the package was a method-of-moments (MoM) fitting routine based on the original paper’s suggestions in sections 4.2 and 4.3. The 1997 paper was a bit vague on the mechanics, so I wrote my own expectation-maximization type algorithm which depends on the difference between the expected value of the second moment and the point-mass at 1. It worked well, but there are some samples for which it simply did not converge; samples for which the “implied” point mass is not positive. This bothered me, and the package was left in development mode (main version 0).
Recent Updates
A short time ago, in early 2026, Dr. Bernegger published a new paper which describes the distribution more completely and also provides pseudocode for a fitting algorithm, using the mean and cv as opposed to the first two moments. I was now able to implement the grid search! What I found was that samples which were problematic for my algorithm also failed to properly converge under the grid search. For those who have read the 2026 paper, the  and
and  curves did not intersect.
curves did not intersect.
As part of revisiting the fitting algorithm, looked at three implementations: an actual grid-search, two-dimensional nonlinear fitting—Nelder-Mead on  and
and  simultaneously, and a nested pair of one-dimensional fits, where the unidimensional fit on calls the one on . All three returned functionally the same answers, and the same as the EM algorithm I originally wrote. I decided to implement the nested 1D fits as that was the fastest of the three.
simultaneously, and a nested pair of one-dimensional fits, where the unidimensional fit on calls the one on . All three returned functionally the same answers, and the same as the EM algorithm I originally wrote. I decided to implement the nested 1D fits as that was the fastest of the three.
Mature Release
Now, I feel much better about the fitting algorithms, in that there are some samples that simply don’t lend themselves to MoM fitting. Anyway, maximum likelihood is almost always more robust if you have the actual observations. The MoM routine is nice in that if all you have are the moments, you can still find a fit—much of the time. With that done, and a slew of code review and hardenings, I felt it was time for the MBBEFDLite package to have its mature release, so version 1.0.0 is now on CRAN. If you happen to use it, I would appreciate any constructive criticism you may have! There is more detail in the functions’ documentation, the NEWS, and the commit comments. Enjoy!